区块链扩容的关键欺诈和数据可用性证明,在这篇论文中,作者们提出、实施并评估了一个完整的欺诈和数据可用性证明方案,并且根据附加的假设:网络中至少有一个诚实全节点在最大网络延迟内传播欺诈证明,并且网络中具有最小数量的轻客户端来共同恢复区块,它使得轻客户端几乎可以得到全节点级别的安全保障。

(图片来自:Institut Friedland)
1 伦敦大学学院
{m.albassam,a.sonnino}@cs.ucl.ac.uk
2 以太坊研究组织
vitalik@ethereum.org
摘要:轻客户端,也被我们称为简单支付验证(SPV)客户端,这类节点只需下载区块链中一小部分的数据,并使用间接的手段来验证给定区块链是有效的。通常,它们假设区块链共识算法所支持的链只包含有效区,并且大多数区块生产者都是诚实的,而不是去验证区块数据。通过降低这类客户端来接收由全节点生成的,表明违反协议规则的欺诈证明,并将其和概率抽样技术相结合,以验证区块中所有数据实际是可用于下载的,我们可以淘汰掉多数人诚实的假设,相反地,对重播数据的最小数量诚实节点,提出了更弱的假设。欺诈和数据可用性证明,是区块链链上扩容的关键(例如,通过分片技术或大区块),同时确保链上数据的可用性和有效性。
我们提出、实施并评估了一个新的欺诈证明,以及一个数据可用性证明系统。
一、和动机
随着密码货币和智能合约平台被广泛采用,我们在实践过程中已经看到了区块链的可扩展性限制问题。由于比特币交易的平均费用一度高达20美元 [19.28],很多流行的比特币支付服务停止接受了比特币支付方式[26],而以太坊流行的CryptoKitties(加密猫)[6]智能合约一度造成以太坊网络未确认交易积压增长了6倍[40]。由于区块链链上空间是受到限制的,例如比特币的区块大小限制 [2]或以太坊的区块gas限制[41],用户们就需要为交易纳入区块链而支付更高的交易费用。
虽然扩大链上容量限制将产生更高的交易吞吐量,但人们会担心这种方式会降低区块链的去中心化及安全性,因为这会导致增加完全下载和验证区块链所需的资源,从而导致更少的用户能够负担得起独立验证区块链的全节点,这就要求用户转而去运行轻客户端,该客户端假设是有遵循区块链协议规则的共识算法 [23]。
轻客户端在正常情况下的运行是良好的,但当多数人的共识(例如矿工或区块生产者)是不诚实的时候,轻客户端的安全保证就是较弱的。例如,尽管在比特币或以太坊网络中的多数非诚实节点,目前只能审查、反转或重新排序交易,如果所有的客户端都使用的是轻节点,大多数共识将能够相互勾结,产生包含凭空创造货币的交易区块,而轻节点将无法检测到这一点。另一方面,全节点将立即拒绝那些无效区块。
因此,各种集中于链外扩容的技术解决方案尝试在兴起,例如支付通道[31],其中参与者在链外签署交易,并最终在链上进行余额结算。支付通道也已扩展到了状态通道 [25]。然而,由于开通和结算通道涉及到了链上交易,因此链上扩容对于支付和状态通道的大规模采用而言,仍然是必要的[3].
在这篇论文中,我们通过使轻客户端能够接收和验证来自全节点的无效区块欺诈证明,以降低链上扩容与安全性之间的权衡,这样它们也可以拒绝它们,前提是,假设至少有一个诚实全节点愿意生成在最大网络延迟的情况下传播的欺诈证明。
我们还设计了一个数据可用性证明系统,这是对欺诈证明的必要补充,以便轻客户端能够保证全节点生成欺诈证明所需的区块数据是可用的,鉴于有少量的诚实轻客户端要重建区块中的丢失数据。我们对自己的总体设计进行了实施,同时评估了安全性和效率。
我们的工作还涉及了区块链分片扩容方案 [1.7.20],而在一个分片系统中,网络中不需要有节点下载并验证所有分片的状态,因此,我们就需要欺诈证明从恶意分片中检测出无效区块。
二、背景
2.1 区块链模型
简单地从字面上讲,区块链的数据结构是由区块串联成链组成的。每一个区块包含两个部分:一个区块头以及一个交易列表。区块头除了存储其它元数据之外,它还会存储之前区块的哈希值(从而实现链的特性),以及包含区块所有交易的默克尔树(Merkle tree)根。
区块链网络拥有一种共识算法 [3] ,以确定一旦发生分叉时,我们应该支持哪一条链,例如,如果使用的是工作量证明 [26]算法,那么累积工作最多的那条链会得到承认。它们还具有一组协议规则,规定链的哪些交易是有效的,因此包含无效交易的区块永远不会被共识算法所青睐,实际上,这些无效交易区块也应该会被拒绝。
而所谓全节点,会下载区块链中的所有区块头及交易列表信息,并根据一些协议规则验证这些交易是否是有效的。
而轻客户端只需下载区块头信息,并假定交易列表中的交易是符合协议规则的。轻客户端根据共识规则验证区块,而不是根据协议规则,因此其假定共识规则是诚实的。轻客户端可以从全节点中接收Merkle证明,其中一笔特定的交易或状态对象被包含在区块头中。
目前有两种主要类型的区块链交易模型:未花费交易输出 (UTXO)模型以及帐户模型。基于UTXO模型区块链的交易(例如比特币),包含了对先前交易的引用,其中哪些币是他们希望去“花费”的。由于单笔交易可能将币向多个地址发送,一笔交易具有很多的“输出”,因此,新的交易包含了对这些特定输出的引用。每一个输出只能够花费一次。
另一方面,基于帐户模型的区块链(例如以太坊),则相对更容易使用(虽然有时在应用并行处理技术时会显得更复杂),因为这种模型下,每笔交易会简单地指定从一个地址到另一个地址,而不会引用先前的交易。在以太坊中,区块头还包含Merkle树根(包含状态),其包含了验证下一个区块所需要的‘当前’信息;在以太坊当中,这包含了系统中所有帐户和合约的平衡、代码及永久存储。
2.2 默克尔树(Merkle Tree)和稀疏默克尔树(Sparse Merkle Tree)
默克尔树是一种二叉树,其中每个非叶节点(non-leafnode)通过其子节点连接的加密哈希值标记。而默克尔树的根,是对所有叶节点中所有条目的的一个保证。这就允许了给出一些默克尔树根的默克尔证明,这些证明能够表明一个叶节点是默克尔树的一部分。
某些叶节点的默克尔证明,是由叶节点的祖节点及祖节点同胞中间节点组成的,直到树的根,从而形成子树,该子树的Merkle根可以被重新计算,以验证Merkle证明是有效的。一棵拥有n叶节点的梅克尔树,其Merkle证明的大小和验证时间是O(log(n))。
而所谓的稀疏默克尔树 [12. 21] ,是指那些拥有n叶节点的默克尔树,而其中的n是一个非常大的数字(例如,n =2^256),但几乎所有的节点都具有相同的默认值(例如,0)。如果k个节点的值是非零点,那么在默克尔树的每个中间层,将有一个最大值k的非零值,并且所有其它值都会是该级别的相同默认值:底层为0.L1= H(0. 0),第一个中间层为L1 = H(0. 0),第二个中间层为L2 = H(L1. L1) ,依此类推。
因此,尽管默克尔树中的节点数呈指数增长,但树的根还是可以通过O(k × log(n))时间进行计算的。稀疏默克尔树允许对键值图进行保证,其中的值可以在O(log(n))时间内进行更新、插入或删除操作。如果构造地简单,则特定键值条目的Merkle证明,就是log(n)的大小,如果中间节点的同胞节点具有默认值是不需要显示的,那么我们可以将其压缩至log(k)大小。
像瑞波和以太坊这样的系统,目前所使用的是帕特丽夏树(Patricia tree)[35.41],而不是稀疏默克尔树;我们在本文中使用稀疏默克尔树为例,是因为它们会更简单。
2.3 擦除码与里德-所罗门码(RS 码)
擦除码是在位擦除(而非位错误)假设下工作的纠错码[14.30];特别是,用户知道哪些位是必须被重建的。纠错码会把长度为k的消息转换为长度为n >k的更长的消息,从而可以从n个符号的子集恢复原始消息。
里德-所罗门码[39]具有多种应用,它是被研究最多的纠错码种类之一。一个RS码通过将长为k的消息作为某些有限域(素数域和二元域是最常用的)元素x0.x1.…,xk−1列表来编码数据,对多项式 P(x) 进行插值处理,其中 P(i) =xi,其中0 ≤ i < k,然后用xk,xk+1.…,xn−1来延伸这个列表,其中xi = P(i)。
这个多项式P可使用诸如拉格朗日插值(Lagrange interpolation)技术,或者诸如快速傅立叶变换法(Fast Fouriertransform)这类更优化、更高级的技术,从这个较长列表中的任何k字符中恢复,而知道P之后,我们就可以恢复原始消息。RS编码可以检测并校正高达(n−k)/2 种错误,或者是错误和擦除的组合。
通过各种方式 [34.37.42],RS码已被推广到了多维码[13.36]。在一个d维码中,消息被编码成大小为k × k × … ×k的正方形或立方体或混合立方体,而一个多维多项式P (x1. x2. …, xd)是在P(i1.i2.…,in) =xi1.i2…,in处进行插入,这个多项式将扩展到更大的n×n×…×n正方形或立方体或超立方体。
三、假设与威胁模型
在我们提出的网络和威胁模型下,我们的欺诈证明(第四章内容)和数据可用性证明(第五章内容)是可以适用的。
3.1 准备工作
我们提出了一些原语,而在论文的其余部分,我们将会使用到这些原语。
1、–hash(x)是一种加密安全哈希函数,它会返回X的摘要(例如SHA-256);
2、– root(L) 会返回项目L列表的Merkle根;
3、– {e → r} 指出了Merkle证明,其中元素e是根为r的Merkle树的成员;
4、– VerifyMerkleProof(e, {e → r}, r, n,i)是当Merkle证明有效时,它会返回“true”值,其它情况则会返回“false”值,其中n表示基础树中元素的总数,而i是树中E的索引。这验证了e是在i索引当中的,及其成员资格;
5、– {k, v → r} 指出了一个Merkle证明,其中键值对k, v是根为r的稀疏Merkle树的一个成员。
3.2 区块链模型
我们假设了一个通用区块链体系结构,其中区块链是由区块头H =(h0.h1.…,hn)组成的哈希链组成的。每一个区块链头hi包含了Ti交易列表的Merkle根txRooti,这样root(Ti) 就等于 txRooti。假设一个节点从网络中下载了交易 Ni的列表,如果(i) root(Ni) = ri,并且(ii) 给出一些有效性函数。那么我们认为区块头hi是有效的。
valid(T, S) ∈ {true, false}
其中T是交易列表,而S是区块链的状态,那么valid(Ti,Si−1)必须返回“true”值,其中Si是在Ti中所有交易之后区块链的状态。我们假设valid(T,S)需要O(n)时间来执行,其中的n是T列表中的交易数。


在第四章第二节中,我们将解释基于UTXO(例如比特币)以及帐户模型(例如以太坊)的区块链如何以用这个模型来表示。
目标:我们的目的是向客户端证明,对于给定的区块头hi,valid(Ti, Si−i)在少于O(n)时间及少于O(n)空间的情况下会返回“false”值,这依靠的是尽可能少的安全假设。
3.3网络模型
我们假设了一个由两种类型节点所组成的网络:
1、全节点。这些节点会下载并验证整个区块链。诚实的全节点会存储和重播它们下载到其它全节点的有效区块,并将与有效区块相关联的区块头广播给轻客户端。这些节点当中,有一些可能会参与共识(通过生产区块)。
2、轻客户端。这些节点的计算能力和网络带宽太低,无法下载和验证整个区块链。它们从全节点那里接收区块头信息,并根据要求,Merkle证明是证明某些交易或状态是区块头的一部分。
我们假设了一个网络拓扑,如图1所示;全节点之间会互相通信,而轻节点客户端则会和全节点进行通信,但轻节点之间并不会互相通信。此外,我们假设了一最大值的的延迟&网络,这样的情况下,如果一个诚实节点可以连接到网络,并在时间T下载一些数据(例如一个区块),那么它会保证其它诚实节点将在T‘≤T+&的时间做同样的事。
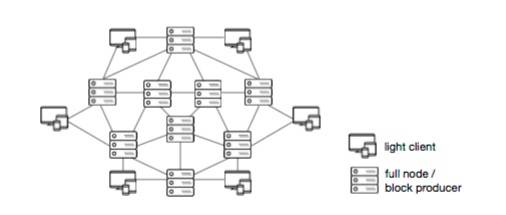
图片1: 网络模型 :全节点之间会相互通信,但轻节点只会和全节点通信
3.4 威胁模型
我们在威胁模型中做出了如下假设:
1、区块和共识。区块头可能会由敌对参与者创建,因此可能是无效的,并且不存在我们可依赖的诚实多数共识参与节点;
2、全节点。全节点可能是不诚实的,例如,它们可能不会中继信息(例如欺诈证明),或者它们可能会中继无效区块。然而,我们假设至少有一个诚实全节点连接到网络(即,它是在线状态的,它愿意生成和传播欺诈证明,并且不受日食攻击(eclipse attack)[18])
3、轻客户端。我们假设每个轻客户端会连接至少一个诚实的全节点。对于数据可用性证明,我们假设最小数量的诚实轻客户端允许区块的重构。具体的数目取决于系统的参数,我们将在第五章第六节中进行具体分析。
四、欺诈证明
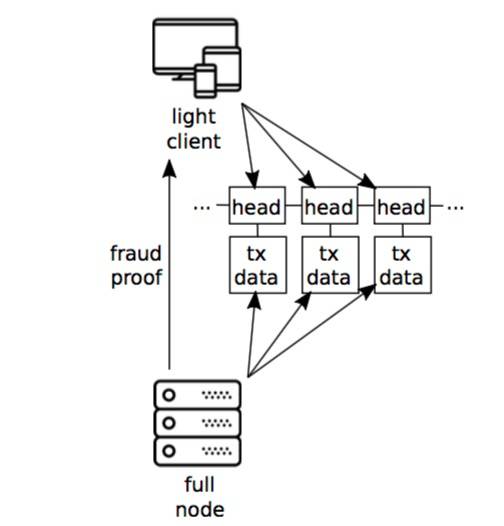
图片2:网络级欺诈证明系统的结构概述
4.1 区块结构
为了支持高效的欺诈证明,有必要设计一个支持欺诈证明的区块链数据结构。该模型的扩展描述详见第三章第二节部分,在区块高度i的区块头hi包含了以下元素:
1、prevHashi :区块链中先前区块头的哈希;
2、dataRooti:区块中包含数据(例如交易)的Merkle树根 ;
3、dataLengthi:由dataRooti所表示的叶节点的数量;
4、stateRooti :区块链状态的稀疏Merkle树的根(详见第四章第二节);
5、additionalDatai:网络可能需要附加的任意数据(例如在工作量证明网络中,这可以包括随机数和目标难度阈值);
此外,每个区块头blockHashi = hash(hi)的哈希,也会由客户端和节点存储。
请注意,典型的区块链具有包含在区块头中的交易Merkle根。我们将其抽象化成“数据的Merkle根”,并命名为dataRooti,正如我们将在第四章第三节内容中看到的,以及包括在区块数据中的交易,我们还需要纳入中间状态根。
4.2 状态根以及执行跟踪构造(State Root and Execution Trace Construction )
为了实例化一个基于上述第三章第二节内容中描述的状态模型的区块链,我们使用了稀疏Merkle树,并将状态表示为key值map。我们解释了UTXO模型和帐户模型的区块链如何可在这样的模型上进行实例化:
1、基于UTXO模型的。map中的key是交易输出标识符,例如hash(hash(d)||i),其中d是交易的数据,而i则是d中涉及的输出的索引。每一个key的值是每个交易输出标识符的状态:要么未使用(1)或者不存在(0.默认值)。
2、基于帐户模型。其已经有了一个key值map,其中的key是帐户或存储变量,而值是帐户余额或变量的值;
状态将需要跟踪所有和区块处理相关的数据,包括例如在每次交易之后,支付给当前区块创建者的累积交易费用。
我们在第三章第二节内容中定义了一个函数转换的变体,称之为rootTransition,它不需要整个状态树,而是只需要交易读取或修改所需的状态树的状态根以及Merkle证明部分(我们称之为“验证”部分,或简称为w)这些Merkle证明被有效地表示为具有相同根的同一状态树的子树。
rootTransition(stateRoot,t,w) ∈ {stateRoot′,err}
验证部分w是由一组key值对及其相关在状态树中的稀疏Merkle证明所组成的,其中,
w={(k1.v1.{k1.v1 →stateRoot}),(k2.v2.{k2.v2 → stateRoot}), …, (kn, vn, {kn,vn → stateRoot})}.
在对w所示的状态部分执行t之后,如果t修改了任何状态,那么可以通过使用修改后的叶节点计算新子树的根,来生成新的结果stateRoot′。如果w是无效的,并且不包含在执行期间t所需的所有状态部分,则会返回“err”;

4.3 数据根和周期(Data Root and Periods)

图片3: 256字节share的例子
由一个包含交易的区块的dataRooti所表示的数据,并排列成固定大小的数据块,我们称之为‘share’,散布在中间状态根,我们称之为交易之间的‘trace’。我们把trace(ji)表示为区块i中第j个中间状态根。我们有必要将数据安排到固定大小的shares当中,以允许我们的数据可用性证明(详见第五章内容)。数据树中的每一个子叶都代表一个share。
因为一个share可能不会包含整个交易,而是只包含交易的一部分(如图3所示),我们可以保留每个share中的第一个字节,作为在share中开始的第一笔交易的起始位置,或者如果没有交易在这个share中开始,则保留0.这允许协议消息解析器不需要区块中所有交易的情况下,就能够建立消息边界。
给定一个share列表( sh0. sh1. …, shn ),我们定义了一个parseShares函数,该函数解析了这些share并输出一个t消息(m0. m1. …, mt)的有序列表,这些消息要么是交易,要么是中间状态根。
例如,在某些区块i的中间部分的某些share实施
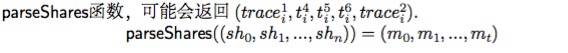
注意,由于区块数据不一定在每笔交易后都包含中间状态根,因此,我们假定了一个“周期规则”,即定义中间状态根的协议规则,应该被纳入区块数据当中。例如,该规则可以每次执行至少p笔交易,或者b子节或者 g gas(例如以太坊 [41])。

注意,如果没有前状态根被解析,那么tracex可以为”nil”(零),因为如果区块中的第一条消息正在被解析,那么就可能会发生这样的情况,因此,前状态根是先前区块stateRooti−i的状态根。同样的,如果没有后状态根被解析,那么trace(x+1)也可以是零。换言之,如果区块中的最后一个消息被解析,后状态根将是stateRooti;
4.4 无效状态转移的证明(Proof of Invalid State Transition)
一个有缺陷的,或者恶意的矿工,可能会提供不正确的stateRooti。我们可以使用dataRooti中提供的执行跟踪来证明执行跟踪的某些部分是无效的。
我们定义了一个VerifyTransitionFraudProof函数,及其相关参数,用于验证从全节点那接收的欺诈证明。如果欺诈证明是有效的,那么拥有这个欺诈证明的区块将永久被客户端拒绝。

如果下列的条件得到满足,VerifyTransitionFraudProof返回的值就是“true”,其它情况则会返回“false”值;


4.5 交易费用
正如我们在本章第2节部分中所讨论的,状态将需要跟踪与区块处理相关的所有数据。一个区块生产者可以尝试收集比区块交易能够承受的更多的交易费用。为了让欺诈证明能够检测到这一点,我们可以在状态树中引入一个特殊的key,我们称之为费用( fee),它表示应用每笔交易后区块中累积的费用,并且在应用交易之后被重置为0.其中区块生产者会收取这些费用。
五、数据可用性证明
恶意区块生产者可以通过扣留验算dataRooti所需的数据,并且仅释放出区块头信息,来阻止全节点生成欺诈证明。然后,区块生产者只能在区块发布很久之后释放数据(其中可能包括无效交易或状态转换),并使得区块无效。这将导致未来区块账本的交易回滚。因此,轻客户端必须要有一定程度的保证,即数据匹配dataRooti确实可用于网络。
我们提出了一种基于里德所罗门(RS)擦除编码的数据可用性方案,其中轻客户端请求数据的随机share,以获得高概率的保证,所有与Merkle树根相关的数据是可用的。该方案假定有足够多诚实的轻客户端做出相同的请求,使得网络可以恢复数据,当轻客户端将这些share上传到全节点时,如果一个全节点并没有完整的请求数据。对于轻客户端来说,确保所有交易数据都是可用的,这是最为重要的,因为只需扣留几个字节,就可以在一个区块中隐藏一笔无效交易。
我们会在本章第7节内容中定义以下的合理性和一致性,并对它们进行分析。
定义1(稳固性Soundness):如果一个诚实轻客户端接受了一个可用的区块,则至少有一个诚实全节点具备完整的区块数据,或者在一些已知的最大延迟k∗δ的情况下,具有完整区块数据,其中δ是最大网络延迟。
定义2(一致性 Agreement):如果一个诚实轻客户端接受了一个可用的区块,那么所有其它诚实轻客户端将在一些已知的最大 延迟k∗δ的情况下,接受该区块是可用的,其中δ是最大网络延迟。
5.1 稻草人1维里德所罗门可用性方案(Strawman 1D Reed-Solomon Availability Scheme)
为了让大家更好的了解,我们首先描述了一个基于标准里德所罗门(RS)编码的稻草人数据可用性方案。
一个区块生产者编译了一个包含k个share的数据区块,并使用RS编码,以及在扩展数据上计算一个Merkle根(dataRooti),以此将数据扩展到2k share,其中每个分叶对应一个share。
当轻客户端接收到具有此dataRooti的区块头时,它们将随机地从dataRooti所表示的Merkle树中采样出share,而一旦它收到所有要求的share时,将只接收一个区块。如果一个敌对区块生产者创建了超过超过50%比例的不可用share,使得整个数据不可恢复(回忆下第二章第三节内容中提到的,RS码允许从任何t share中恢复2t的share),则一个客户端有50%的机会在第一次抽取活动中随机抽到一个不可用的share,两次抽取后有25%的机会,三次抽取后有12.5%的机会,依此类推,如果它们用替代者来抽签(在完整的方案中,它们将在没有替换的情况下进行抽签,因此概率甚至会更低。)
注意,为了使该方案工作,网络中必须要有足够的轻客户端来抽样足够的share,使得区块生产者将需要释放超过50%的share,以便通过所有轻客户端的采样挑战,从而可以恢复完整的区块。在本章第六节内容中,我们提供了深入的概率和安全性分析。
该方案的问题是,一个敌对区块生产者可能会错误地构造扩展数据,因此,即使有超过50%的数据是可用的,不完整的区块也无法从扩展数据中得到恢复。
而使用标准RS编码,使得扩展数据是无效的欺诈证明,是原始数据本身,由于客户端将不得不重新编码本地所有数据,以验证给定扩展数据的不匹配,因此,它需要关于区块大小的O(n)数据。因此,我们改为使用了多维编码,如本章第二节内容所述,以便将错误生成代码的证明限制在特定轴上(而不是整个数据),将证明大小减小到
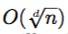
其中d是编码的维数。为了简单起见,本文只考虑二维的RS编码,但实际我们的方案可以推广到更高的维度。
我们在第七章第一节内容中,会提到简洁的计算证明可以替代多维编码,成为这个问题的未来解决方案。
5.2 二维RS编码Merkle树构造
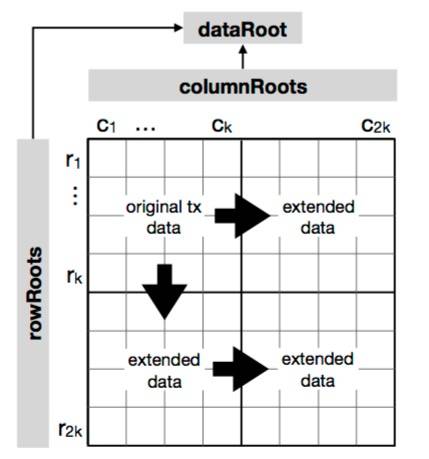
图片4:二维RS编码图。
原始数据初始排列成k*k矩阵,然后应用多次RS编码,将其扩展成2k * 2k矩阵。
一棵二维RS编码Merkle树可以是如下数据块构造:


请注意,尽管可以从dataRooti向单个share呈现一个Merkle证明,重要的是要注意Merkle树具有2^x的子叶,而行与列根的 Merkle子树是独立于dataRooti构造的。因此,在VerifyMerkleProof周围必须有一个称为VerifyShareMerkleProof的封装函数,该函数具有相同的参数,它会涉入到帐户,考虑底层Merkle树如何处理不平衡数的子叶;这可能会涉及为路径的不同部分调用两次VerifyMerkleProof函数,或者抵销索引。
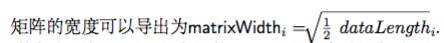
如果我们只关心dataRooti的行和列根,而不是实际的share,那么在验证行或列根的Merkle证明时,我们可以假设dataRooti 具有2*matrixWidthi的子叶。
一个轻客户端或全节点能够通过重新计算步骤4.从所有行和列根重构dataRooti 。为了获得数据可用性保证,所有轻客户端至少应该下载重构dataRooti所需的所有行和列根,并检查步骤4是否被正确计算,因为正如我们将在本章第五节内容中看到的,它们必须生成错误扩展数据的欺诈证明。
尽管如此,我们将所有行根和列根表示为单个dataRooti,以允许无需下载行列根的“超轻”客户端,但是这些客户端无法保证数据可用性,因此不能充分受益于允许欺诈证明的安全增加。
5.3 随机抽样和网络区块恢复
为了使2维RS矩阵中的任何share不可恢复,那么在2k share当中,至少有 (k + 1)^2 share必须是不可用的(参加定理1)。因此,当轻客户端从网络接收到新的区块头时,它们应该从扩展矩阵中随机采样0 < s < (k + 1)^2 份独特的share,并且只有当它们接收到所有share时才会接收区块。此外,轻客户端向网络传递它们已经收到的share,以便诚实的全节点可以恢复整个区块。
轻客户端与它连接的全节点之间的协议如下:


5.4 选择性Share披露
如果一个区块生产者按轻客户端的要求,有选择地释放share,并且最多为(k + 1)^2 share,那么他们可能违反了客户端的稳固属性(定义1),该客户端请求2k share当中的第一部分(k + 1)^2 share,因为他们将接受这些区块作为可用的,尽管它们是不可恢复的。
如果假设一个增强的网络模型,其中有足够多数量的诚实客户端做出请求,使得多于 (k + 1)^2 share被采用,并且每一个针对share的样本请求是匿名的(即,样本请求不能连接到同一个客户端),并且每个样本请求被接收的分布是均匀随机的,(例如使用混合网络[9])则可以减轻这一点。由于网络不能将不同的share样本请求连接到同一个客户端,share就不能根据每个客户端随机性地释放。
因此,我们假设了两个可进行样本请求的网络连接模型,我们将在安全分析部分对其进行分析:
1、标准模型。样本请求可连接到产生它们的客户端,并且它们被接收的顺序是可预测的(例如,它们按照发送的顺序被接收)。
2、增强模型。不同的样本请求不能连接到相同的客户端,并且网络接收它们的顺序较其它请求是一致随机的。
5.5 错误生成扩展数据的欺诈证明(Fraud Proofs of Incorrectly Generated Extended>

让我们来恢复一个函数,它获取了share列表及其在行或列中的位置((sh0.pos0),(sh1.pos1),…,(shk,posk)),然后扩展行或列2k的长度。如果share是不可恢复的,则函数输出那些完全恢复的share(sh0.sh1. …, sh2k) 或者为“ err ”。
recover(((sh0. pos0), (sh1. pos1), …, (shk, posk)), 2k) ∈ {(sh0. sh1. …,sh2k), err}
当满足以下所有条件时,则VerifyCodecFraudProof返回“ true”值:

请注意,全节点可以指定行或列中的share Merkle证明。

5.6 抽样安全性分析
对于第五章内容中提供的数据可用性方案,我们将介绍其如何为轻客户端提供了区块数据可用性的高度保证。
不可恢复的最少不可用Share(Minimum Unavailable Shares for Unrecoverability)定理1中指出,如果恶意区块生产者扣留至少k + 1行或列的k + 1 share,则数据将是不可恢复的;这使得总共 (k + 1)^2 数量的share会被扣留;
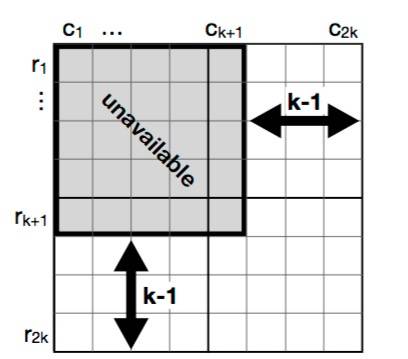
图片5 :定理1的图解,如果至少有 k + 1行或列中k + 1的share是不可用的,则数据就是不可恢复的。
定理1 。在图4所示的2k × 2k矩阵E中,如果至少有k + 1列或行具有至少k +1的不可用share,则数据就是不可恢复的。在这种情况下,必须是不可恢复的share的最小数量为(k + 1)^2;
证明:假设恶意的区块生产者希望使2k×2k矩阵E中的Ei,j share变得不可恢复,(回想一下,RS编码允许从任何k share当中恢复所有2kshare);区块生产者必须(i)从行 Ei,∗中让至少 k + 1 share变得不可恢复,并且 (ii) 从列 E∗,j 中让至少 k + 1share变得不可恢复;
让我们从 (i)开始论述:区块生产者至少要从行 Ei,∗中扣留k + 1 share。然而,这些k + 1中的每一个扣留share (Ei,c1 , .. . , Ei,ck+1 ) ∈ Ei,∗ 可以从它们各自的列E∗,c1. E∗,c2…, E∗,ck+1中恢复。因此,区块生产者还必须要从这些列中扣留至少k + 1的share。这意味着区块生产者需要扣留的share数为 (k + 1) ∗ (k + 1) = (k+ 1)^2.
然而,(i) 通过矩阵的对称性等价于 (ii),并且实际上是在相同的share上进行操作;在矩阵E上执行(i)等价于对矩阵E的转换上执行(ii)。
不可恢复区块检测。定理2陈述了单个经客户端将以不可恢复性的最小不可用share对矩阵中至少一个不可用share进行采样的概率,从而检测一个区块可能是不可恢复的。
定理2.给定一个2k × 2k矩阵E,如图4所示,其中 (k + 1)^2 个share是不可用的。如果一个参与者随机从矩阵E中抽样0 < s< (k + 1)^2 个share,那么至少有一个不可用share的抽样概率是:
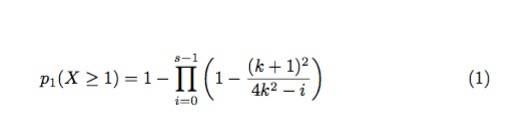
证明。我们假设这个2k * 2k矩阵E包含了q个不可用share,如果参与者执行s次试验 (0 < s < (k + 1)^2),则找到0个不可用share的概率为:
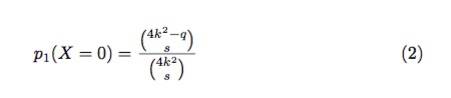
等式(2)的分子,计算的是不可用share集合
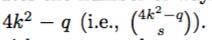
中计算选择的s的方法数量。分母计算的是从样本总数中

挑选任何s样本的方法数量。
然后,我们可以从等式(2)容易地计算出找到至少一个不可用share的概率p1(X ≥ 1)
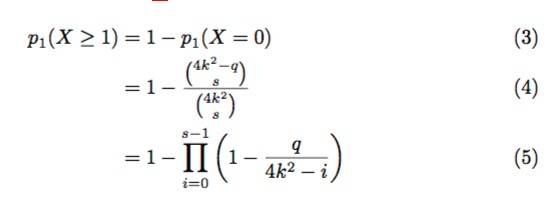
我们可以通过设置q = (k + 1)^2.将其重写为等式(1);
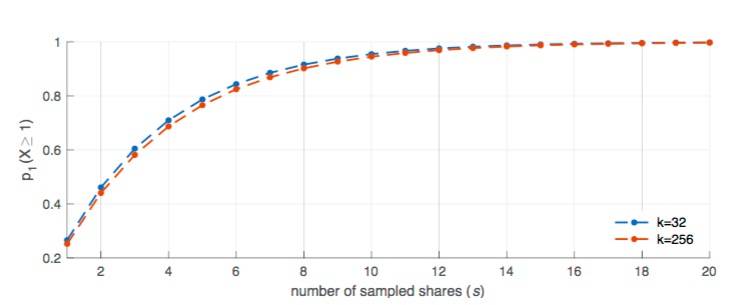
图6:等式(1)的绘图 ,概率P1(X ≥ 1)抽样 share的数量变化(计算 k = 32 和 k = 256)。
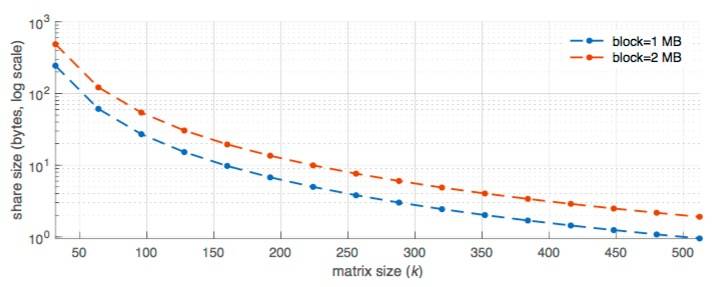
图7:share大小与矩阵(k)大小的变化。
图6显示了这种概率如何随k = 32 和 k = 256 的s个样本而变化;每个轻客户端在进行3次采样后约有60%的概率至少有一个不可用share(即分别查询k = 32时,区块share的概率为0.07%,k = 256时,区块share的概率为0.001%),在15次采样后,这个概率超过了99%(即分别查询k = 16时,区块share的概率为0.4%,k = 256时,区块share的概率为0.005%)。图7显示,轻客户端必须下载大约3.6 KB share才能检测到不完整的区块,对于k = 32时,这个概率超过99%,而k = 256时,大约为57 字节的share。
等式(6)显示了一个显而易见的结果:对于较大的k值,概率p1(X ≥ 1)几乎与 k无关了;因此具有大的矩阵大小(即,k ≥ 128)是实用的,因此这减少了轻客户端必须下载的数据量。
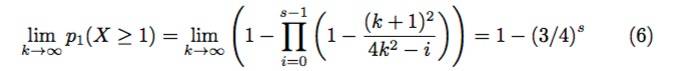
根据第五章第四节中描述的增强模型,恶意区块生产者可以基于它们查询的的share来统计连接的轻客户端;即,假设轻客户端永远不会请求两次相同的share,区块生产者可以以此推断对相同share的任何请求都来自不同的客户端。为了缓解此问题,轻客户端可以通过多次执行替换采样,并且仅在采样到唯一值时才会停止。
多客户端不可恢复区块检测。定理3,在一个具有不可恢复性最小不可用share的矩阵当中,从c个轻客户端样本中捕获超过cˆ样本,并且至少有一个不可用share的概率。
定理3.给定一个2k × 2k矩阵 E,如图4所示,其中有 (k + 1)^2 share是不可用的。如果有c位参与者从矩阵E中随机抽样出0 < s< (k + 1)^2份share,则超过cˆ参与者样本,至少有一个不可用share的概率是:
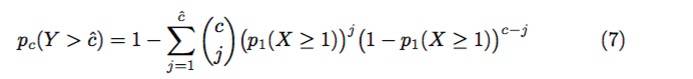
其中p1(X ≥1)是由等式(1)给出的。
证明:首先我们计算了cˆ位参与者样本至少有一个不可用share的概率,这个概率是通过二项式概率质量函数计算得出的:
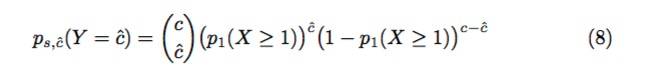
其中p1(X ≥ 1)是由等式(1)给出的,等式(8)描述了cˆ 位参与者成功采样到至少一个不可用share的概率。这可以看作是观察cˆ每一次以成功率p1发生的概率,以及以成功率1 − p1发生的(c − cˆ)失败率;这些成功和失败排序的可能方法有 (c cˆ)种。
等式(8)很容易地就可以扩展到等式(9)中的二项式累积分布函数,即在j = 1. . . . cˆ的情况下,观测到最多cˆ成功观测的概率和
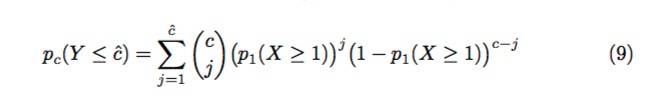
因此,观察到多于cˆ的成功概率由下面的等式(10)给出,它是作为等式(7)的扩展。

图8:等式(7)的制图,描述了轻客户端cˆ数目的变化,其中pc(Y > cˆ) ≥ 0.99随着采样大小S。客户端总数固定于c =1000.矩阵大小为k=64. 128. 256;等式(7)几乎与k无关,如等式(6)所示。
图8显示了轻客户端cˆ的数量变化,其中pc(Y > cˆ) ≥ 0.99随采样大小S。客户端总数固定于c = 1000.矩阵大小为k=64.128. 256;等式(7)几乎与k无关,如等式(6)所示。该图可用于确定具有高概率(pc(Y > cˆ) ≥0.99)的不完全矩阵的轻客户端数量,并且当s增加到15以上时,几乎没有增益。
恢复和选择性 Share披露(Recovery and Selective ShareDisclosure)。推论一给出了轻客户端集体采样足够share以恢复2k × 2k矩阵中每一个share的可能性。
如果轻客户端集体采样了除 (k + 1)^2之外的所有不同share,则区块生产者不能在不允许网络恢复整个矩阵的情况下,释放任何更多的share;根据定理1.轻客户端至少需要收集:
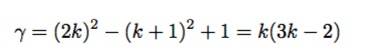
份不同的share(随机选择),以确定能够恢复2k *2k矩阵。因此,我们感兴趣的是,轻客户端每次采样s份不同share,共同采样至少γ 份不同 share的概率,这个概率由推论1表示。
定理4 。 (Euler [15]) 从n个元素集中取样不同元素的数量。

推论1.给定如图4所示的2k*2k矩阵E,其中每c位参与者随机地从矩阵E中抽取不同的share。参与者集体抽取至少γ = k(3k− 2)不同 share的概率是pe(Z ≥ γ)
证明。推论1可通过把λ = n−γ 和 n = (2k)^2代入定理4.以实现容易的证明。

图9. 推论1的图示,概率值 pe(Z ≥ γ) 与客户端(c)在s 和 k值不同的情况下发生的变化
与等式(7)相反,图9表明 pe(Z ≥ γ) 依赖于矩阵的 k大小。
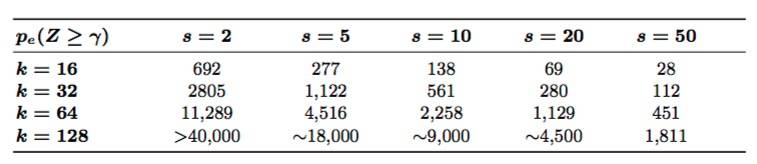
表一:针对不同的k 值和s值,达到 pe(Z ≥ γ) > 0.99所需的最小轻客户端 (c) 的数量。由于评估定理4对于k的大值可能会非常消耗资源,所以我们取了接近值。
5.7属性安全性分析
标准模型
推论2 。在标准模型下,区块生产者不能导致稳固性(定义1)以及一致性(定义2),无法让超过c的诚实客户端概率低于p1(X ≥ 1) ,其中c是由概率分布pe(Z ≥ γ)来确定的。
证明。推论1表明,在概率pe(Z ≥γ)的情况下,c个诚实客户端将采样足够的share,以共同恢复整个区块。诚实的客户端会向全节点传播这些 share,然后这些节点之间彼此会互相传播,并且在k×δ内,至少有一个诚实全节点将随后恢复完整区块数据,因此,以每个客户端1 −p1(X ≥ 1) 的可能性(当所有区块数据可用时,区块生产者不通过客户端随机采样挑战的概率)就可以满足稳固性。
如果数据可用,并且没有客户端收到错误生成的扩展数据欺诈证明,那么也不会有其他客户端会收到欺诈证明。我们假设网络中至少有一个诚实的全节点,并且诚实的轻客户端不会暴露于日食攻击( eclipse attack)之下,从而满足每个客户端1 − p1(X ≥ 1) 的概率。
由于在第五章第四节中描述的选择性share披露攻击,这意味着区块生产者可以违反第一批c客户端发出的样本请求的可靠性和一致性,因为区块生产者可以在其发布最终share之前停止释放share,以阻止区块变为可恢复。
增强模型
推论3.在增强模型下,在每个客户端低于 px(X ≥ 1) 的概率下,区块生产者不能导致稳固性(定义1)以及一致性(定义2),
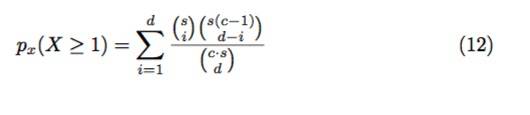
其中c是客户端的数量,d是阻止全节点恢复数据必须拒绝的请求数量。
证明。推论3的证明从推论2的证明开始,诚实的轻客户端通过向全节点传播这些share来收集足够的share样本,以恢复整个区块数据。每一个客户端在概率1−p1(X ≥ 1)时能够满足稳固性的要求。如果区块数据是可用的,轻客户端就不会收到欺诈证明,网络上也不会传播欺诈证明,并且如果发送了一个欺诈证明,则所有的轻客户端最终会收到一个有效欺诈证明,以相同的概率满足了一致性。
然而,增强模型假设所有样本都请求经过一个完美的混合网络(即,请求之间是不可连接的)。并且接触了第五章第四节中提出的选择性share披露攻击。增强模型消除了推论2中描述的‘第一批’客户端的概率,因为区块生产者无法区分哪些请求来自哪个客户端(因为请求是不可能的)。此外,如果区块生产者随机地拒绝一些请求,则轻客户端将统一地看到它们的一些示例请求被拒绝,并且每个轻客户端因此将以相同的概率认为此区块无效。
特别是,如果 c个轻客户端每个样本 0 < s < (k + 1)^2 share,区块生产者观察到总的(c·s)不可区分的请求。让我们假设恶意区块生产者必须至少拒绝d次请求以阻止全节点恢复区块数据。轻客户端观察到其请求中至少一项(因此拒绝区块)的概率是等式(12)中的px(X ≥ 1)。
等式(12)中的分子是计算的由轻客户端发出的s次请求中被拒绝的请求i的方式数目,再乘以其他轻客户端 c · s − s = s(c − 1) 发出的请求当中剩余d − i请求的方式数量。而分母则是计算挑选总请求当中的d请求的方式总数。
与等式(1)类似,等式(12)会迅速增长,并显示出如果区块无效,轻客户端则会拒绝掉此区块(对于适当的d值)。其中d的值可以使用推论1来近似算出,并且它取决于s 和 c。为了让读者更好地了解这个概念,如果我们假设轻客户端对区块的每一个share进行集体采样至少一次,那么恶意区块生产者必须拒绝不同share至少 (k + 1)^2次请求,才能阻止全节点恢复区块数据,因为多个请求可以采样相同的share,其中d ≥ (k + 1)^2;
六、性能与实现
我们实施了第五章内容中描述的数据可用性证明方案,以及第四章内容中描述的状态转移欺诈证明方案的原型。

表2:各种对象的最坏情况空间复杂度。p表示周期内的交易数量,w代表这些交易的验证数量,d是dataLength的简称,s是状态树中的键值对的数量。
整个实现共2683行Go代码,并且我们将其以免费和开源的方式呈现给大家。
(2D Reed-Solomon Merkle tree>
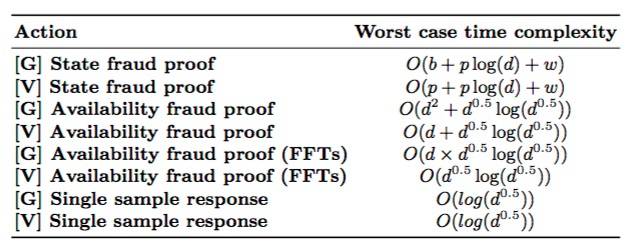
表3:各种动作最坏情况下的时间复杂度,其中 [G] 表示生成, [V]表示验证。p表示周期中的交易数量,b表示区块中的交易数量,w表示这些交易的验证部分数量,d是dataLength的简称,而 s则是状态树的键值对的数量。为了生成和验证状态欺诈证明,我们假设处理每笔交易所花费的时间是相同的。为了生成欺诈证明,我们还纳入了验证区块本身的成本。
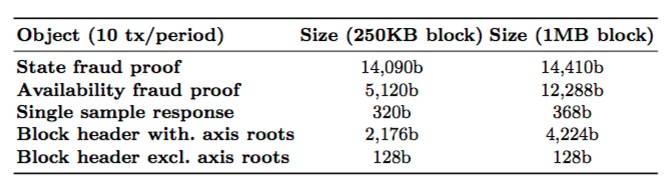
表4:用于250KB以及1MB 区块对象的说明性大小,假设一个周期由10笔交易组成,平均每笔交易大小为225字节,并且保守地说,状态树中有230个非默认节点。
对于区块的大小,这是因为周期中的交易数量保持了静态,但是每个交易的Merkle证明大小略有增加。区块大小影响可用性欺诈证明的大小,而轴根的影响则是最大的,因为单个行或列的大小与区块大小的平方根成比例。
表5显示了用于生成和验证各种对象的计算时间;用于状态欺诈证明生成的基准包括用于验证区块的时间。虽然在区块大小的验证上,它是线性的,但在我们的实施过程中,由于Merkle树中每次更新需要256个哈希操作,因此它具有高的常数因子。这可以通过使用SIMD指令[17]的SHA-256库以及将树分解为子树[11]来实现改进,从而进行并行处理更新。或者,我们可以使用更为复杂的键值树构造,例如帕特丽夏树[41]
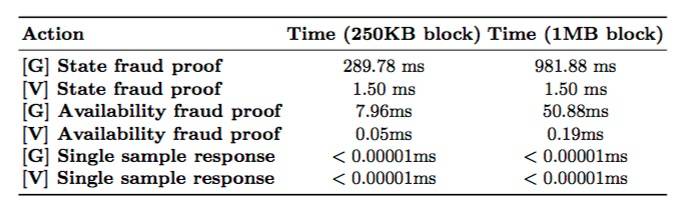
表5:计算用于各种动作的时间(平均超过10次重复动作),其中 [G] 代表生成, [V] 代表验证。我们假设一个周期内由10笔交易组成,平均交易的大小为225字节,每一笔交易会在状态树中写入一个key。
正如预期的那样,验证可用性欺诈证明要比生成更快。这是以为你生成需要检查整个数据矩阵,而验证只需要检查一行或一列。注意,我们使用的是标准的RS算法库,这些算法需要 O(k^2)时间来编码/解码,通过使用基于快速傅氏变换算法,我们可以把时间降低到O(k log(k))。
七、讨论
7.1 简洁的计算证明
在计算的简洁证明方面,我们已经取得了进展,包括zk- SNARKs [5] 以及最近的zk-STARKs [4],这允许证明者证明,对于某些给定的 x 和y ,f(x,W) = y , 其中即使证明部分W是非常大的,并且计算时间f会是非常长的,证明本身只有对数或恒定的大小,并且只需要对数或恒定的时间来验证。
对于将来的工作,我们可以要求区块头附带这样的证明,以表明它们是经过正确的擦除码操作过的,消除欺诈证明的需要。还请注意,2维RS方案相对于1维方案的唯一显著优点,在于更少的欺诈证明,因此如果使用简明的证明,则切换回1维方案可能是最优的(对于n个share,如果使用快速傅立叶变换法 [22.33],则构造合法的擦除代码只需要O(n log(n)) 计算时间)。
注意,虽然可使用区块状态根转移函数的简明证明计算,来消除对欺诈证明的需求,但它们并不能消除对可用性证明的需求。如果多数恶意的区块生产者广播了数据不可用的区块,则它们可以拒绝诚实全节点构造完整最新状态所需的信息,并为涉及某些账户的交易生成验证部分(即,Merkle分支)。这些恶意者通过防止创建验证部分,使用不可用数据的区块,可使账户永久不可访问 [8]。 使用信息论参数表明,即使像密码累加器这样的构造,也不能消除验证O(n)数据可用性的需求,它可以确保所有验证部分都能够被正确更新。
7.2 局部可译码
关于该方案,消除对欺诈证明需求的另一个策略,是使用多维RS码的局部可译码功能[43]。特别地,我们利用数据的Merkle根作为熵源,构造由一组伪随机选择的行与列(或用于更高维编码的轴平行线)组成的“邻近证明”(proof ofproximity),其中,验证者可以验证是否具有< k的度,从而概率地验证所有轴平行线中具有非常高的百分比的
任何具有有效邻近证明的区块(头)都是可接受的,即使扩展多
火币
网苹果官方下载项式数据的一小部分是不正确的。正因为如此,一个单一的Merkle分支,不再足以证明一个单一的值。相反,验证者可选择一个随机的穿过该点的非轴平行线,并要求证明人提供至少线上的(3/2)∗ d点。验证者在期望的点计算正确的值,必要时进行纠错。为了增加可靠性,验证者可以选择多个随机非轴平行线。
该方案的优点在于,它不依赖于欺诈证明或昂贵的计算证明,但它也具有以下的缺点:
(i)它要求在网络上存储更多的编码数据,尽管这种情况下,由于大数量的share可减轻存储在网络上每一个share的拷贝数,但其总体还是会存储更多的编码数据。
(ii)Merkle证明变大了两个数量级。
八、相关工作
最初版的比特币白皮书[26]简要地提到了“警报”的可能性,它是由全节点发送而出的消息,用于警告轻客户端某个区块是无效的,促使它们下载完整的区块以验证数据的不一致性。对此,白皮书进行了很少的探索,部分原因是数据可用性问题。
关于如何设计欺诈证明系统[32.38],社区已经有了在线讨论,但是还没有提出处理所有块无效情况和数据可用性的完整设计。这些早期的系统,已在尝试为创建违反协议规则的区块(例如,双花输入,挖取高报酬区块等)的每种可能方法设计欺诈证明,而本文将区块链推论到仅具有一个欺诈证明的状态转移系统。
在数据可用性方面,Perard等人[29]已提议使用擦除编码来允许轻客户端自愿贡献以帮助存储区块链,而无需下载所有的区块,然而,他们还没有提出一种方案,可允许轻客户端通过随机采样和错误生成擦除编码的欺诈证明,来验证数据是可用的。
九、
我们提出、实施并评估了一个完整的欺诈和数据可用性证明方案,并且根据附加的假设,网络中至少有一个诚实全节点在最大网络延迟内传播欺诈证明,并且网络中具有最小数量的轻客户端来共同恢复区块,它使得轻客户端几乎可以得到全节点级别的安全保障。
致谢
Mustafa Al-Bassam得到了艾伦.图灵研究所的奖学金资助,而Alberto Sonnino得到了欧洲委员会地平线2020 DECODE项目的资助,项目编号为732546.
感谢George Danezis, Alexander Hicks 和 Sarah Meiklejohn对论文数学论证的有益讨论。
什么是ZK-Rollup(零知识汇总)?1. ZK-Rollup是一种基于零知识证明技术的区块链扩容解决方案。
2. 在发送至主链的交易中,ZK-Rollup包含了一个对应的零知识证明,主链上的汇总智能合约仅需验证这一证明。
3. 零知识证明确保了交易细节的隐私性,同时允许通过与智能合约的交互,证明上链数据的完整性和真实性。
4. 优点包括: - 高度去中心化 - 隐私性保护:零知识证明不泄露交易细节 - 上链效率高:批量提交交易,节省时间和燃料费(Gas) - 验证效率高:无需等待期,快速完成资产提取 - 安全性高:零知识技术确保主链数据真实有效,同时保持数据可用性,达到以太坊级别的安全标准。
5. 缺点包括: - 技术开发难度较大 - 难以兼容不同智能合约 - 需要大量计算资源6. 代表项目包括: - 路印:利用成熟的零知识技术,完成私募融资4500万美元,市值超过8亿美元 - ZKSync:致力于为以太坊提供Visa级别的交易吞吐量7. 学硕创新区块链技术工作站是教育部学校规划建设发展中心授权的“区块链技术专业”试点工作站,旨在为学生提供多样化的成长路径,并推进区块链技术专业学位研究生的产学研结合培养模式改革。
目前主要有六种扩容计算方案,分别是分片、侧链、状态通道、Plasma、Rollup、Validium,其中Rollup技术扩容方案还分为ZK Rollup和Optimistic Rollup。
一、分片 (sharding) 方案:分片属于layer1扩容。
是指区块链不同的节点子集处理区块链的不同部分,通过分割数据以减少区块链节点必须存储和处理的数量。
二、侧链方案:侧链协议本质上是一种跨区块链解决方案。
通过这种解决方案,可以实现数字资产从第一个区块链到第二个区块链的转移,又可以在稍后的时间点从第二个区块链安全返回到第一个区块链。
三、状态通道(State Channel)方案:状态通道技术,受启发于比特币的闪电网络。
状态通道是固定一组参与者(通常是两名参与者)之间的协议,用以实现安全的链下交易,其中支付通道专门用来支付。
四、Plasma方案:Plasma由Vitalik Buterin和Joseph Poon(闪电网络创始人) 在2017年共同提出。
Plasma是一种链下交易的技术,从一个新的方向实现了状态通道,它允许创建附加在以太坊主链上的子链,这些子链反过来可以产生他们自己的子链,他们的子链也可以产生他们子链。
五、Rollup方案:Rollup方案可以被认为一种压缩技术,多笔交易可以压缩在一起(几千笔交易可以被打包到一个Rollup区块中),既能减少交易数据规模,又能降低交易验证负担,因此使得以太坊区块链能处理更多交易。
Rollup 方案还分为ZK Rollup和Optimistic Rollup。
1)ZK Rollup是靠着在主链完成零知识证明,链上无需包含签名数据,因为零知识证明就足以证明交易的有效与否,交易有效性就立刻确认,保证无效的状态绝不会发生,也即数据可用性放在链上,所以ZK Rollups对数据存储方面也带来了一定程度上的扩展性提升。
2)Optimistic Rollup 的理念是由John Adler首先构想出来的,它保留了calldata,可以主链获得所有layer2的数据,但那些刷新Layer-2状态的交易不会在链上被验证,只让主链存储一系列的历史状态根,添加了一个新的状态的一段时间(例如 1 周)后才将新状态最终敲定,也就是数据可用性放在链下。
六、Validium方案:Validium是由零知识证明研发机构StarkWare主导开发的,选择将layer2的交易数据放在链下,因而比rollup方案有着更高的扩展性。
我们通过以上关于以太坊扩容方案有哪些内容介绍后,相信大家会对以太坊扩容方案有哪些有一定的了解,更希望可以对你有所帮助。
数据造假、数据不可信等问题的存在,给金融监管及风控等众多应用场景带来了严峻的挑战,也正成为阻碍数据大规模互联互通、共享共用的一大障碍。
数据的真实可信问题长期影响着社会的各个领域,在更依赖数据的人工智能时代,这一影响将更为凸显。
数据造假可能发生在任一环节。
其中,在数据存储期间造假往往更加简单:因为在现有数据存储技术下,数据的所有者、管理人员或受托存储方均有能力单方对数据进行任意的篡改或删除。
既然数据不可信的一个重要原因归咎于单方可以擅自篡改和删除数据,那么如何避免这一问题自然也得到了业界大量的关注。
区块链和去中心化存储技术的诞生,对数据篡改起到了一定的遏制作用,也在市场上取得了初步验证。
许多企业开始尝试采用区块链存储数据,例如在货物追溯等场景。
其做法往往是将重要数据直接写入区块中。
这一简单粗暴的做法确实解决了数据防删改需求、继而满足了部分数据的可信分享,但却存在较多问题:
首先是无法存储海量数据:区块内不适合存储包括多媒体数据等在内的大数据,否则区块大小难以控制,使区块链的可扩展性变差。
这就导致业务中必须对原生数据进行筛选取舍,仅选取少量必要数据存入区块,但这将降低可信数据的丰富程度。
其次是数据存取效率低:首先,由于打包过程的存在,区块链数据存储一般不用于高速的数据写入。
其次,由于遍历式的数据读取方法,区块链无法支持快速索引、更无法支持SQL。
再次是数据维护效率低:区块链因其顺序引用的特点,不支持对个别历史数据的删除和修改(除非对全链重新生成,但这是区块链不应鼓励的行为)。
这里需注意:“杜绝单方的私自篡改”和“完全不能删改”是完全不同的两件事。
前者是一种确保互信的技术手段,但后者可能属于一种必要功能点的丧失。
最后是有数据丢失风险:这一风险单指采用中本聪共识最长链原则的PoW区块链系统。
在这类区块链中,当出现链分叉时,最长(或最重)的链分支会被保留,其他分支会被抛弃,这就使区块内的数据实际上永远存在被“颠覆”、被丢弃的风险。
而自私挖矿等攻击行为的存在,会加剧这一风险。
这在数据存储应用中是无法接受的。
正是由于上述原因,直接采用传统区块链进行数据存储显然无法满足大量实践性场景中对可信数据存储的需求。
这一问题也因而引发了大量的探讨,例如“什么数据应该在链上存储、什么数据应该在链下存储”。
这些问题的出现,究其根本,还是因为区块链自身存储效率及能力受限所致的。
毕竟在数据库时代,我们从来不会谈论“什么数据应该存放在数据库之外”这样的问题。
近年来也出现了一些产品,为解决上述的区块链数据存储效率低下问题提供了有益的实践,例如:
星际文件系统IPFS, R3的Corda,腾讯TrustSQL等。然而这些产品在数据可信存储方面仍存在或多或少的问题,具体而言:
IPFS对数据内容生成哈希摘要,并在多个节点间进行分布式存储,单个保有者不掌握完整数据,一定程度保护了数据隐私。
但IPFS只能做到修改可知(因哈希值会因内容改变而变化),并且没有访问控制等数据安全措施,整体而言仍难以满足企业级服务需求。
Corda是面向金融交易隐私需求量身定做的存储产品,重点关注数据存储的隐私性。
为此,Corda没有全局账本,并需要见证人的存在,是一种隐私但并不足够安全可信的数据存储方案。
TrustSQL与国内其它同类产品采用了一种简单直观的设计思路,也是目前国内最为常见的做法,即:先将数据存入数据库(或IPFS),再将操作记录、数据哈希等存于链上。
相对于TrustSQL而言,一些类似产品如众享比特的ChainSQL等进一步提升了对SQL的支持度。
该类产品满足了数据“可审计”、“监管透明”的需求,但缺点是依然无法杜绝对数据本身的删改行为,只是能做到“删改可知”;此外,对关键数据的保全需要依赖参与节点的全副本存储,存储成本略高。
并且在数据隐私性方面的设计仍显不足。
针对上述产品中存在的不足,物缘科技通过原创技术创新,探索出一条不同的道路,并推出自主知识产权产品“ImSQL”,旨在提供一种可真正确保数据不被私自篡改或删除的可信存储产品。
ImSQL(Immutable SQL Database)是基于区块链和分布式存储技术上的一种新型可信数据存储解决方案,并完美解决了“防止私自删改”、“保护数据隐私”、“降低存储成本”等核心问题,为大数据时代的可信存储与数据分享提供了可靠的技术路径。
相比现有产品,ImSQL具有以下几点突出优势:
1. 彻底杜绝单方对数据的私自篡改和删除。
通过在存和取两个环节进行多方校验并在存储过程中杜绝篡改删除,全方位保障数据的真实可信性,使应用中的参与方能够互信、放心地采纳它方数据,使数据能够支撑精准追溯、追责。
2. 杜绝单点失败。
多方共用数据的同时也共同维护数据,数据不只存于一方,从根本上实现分布式数据的可信共享池,既避免了单点失败风险,也提升了数据分享效率。
3. 碎片化存储,满足数据隐私需求,使任何一方无法掌握完整数据,从而解决了传统云计算的中心化存储、或区块链全副本存储均存在的数据隐私问题。
除了数据所有方,其他任何存储托管者都无法获得完整数据。
4. 优异的数据存取性能:ImSQL单节点可达3000 TPS的写入速度和 QPS的读取速度。
此外,ImSQL还具有:支持SQL语言,可水平扩展等优点,存取性能和使用体验优异,并可充分利用集qun扩展使上述指标进一步达到数倍增长。
5. 满足多媒体等大数据的高效存取需求,支持高效存取、高效索引、高效扩展,真正胜任大数据业务场景,可以对视频等数据实现既可信又高效的存储,从而给视频监控等场景提供前所未有的可信保全体验。
6. 采用分片式设计,极大降低了每个存储参与方的存储压力和成本,使更多参与方有机会加入和参与到数据可信共享的生态中。
7. 分布式架构,兼容轻节点,鼓励更多节点参与。
不存在超能节点,参与存储的节点地位相同,更好保证系统的可靠性和抗毁性。
此外,如果节点选择运行在轻副本模式,可只存储部分数据,使自身存储压力极大降低,义务虽然减轻但权力可不受任何影响。
ImSQL兼顾了海量存储、快速索引、水平扩展等数据库属性,也兼顾了数据即存即固化的区块链特征,在众多关注数据可信存储与分享的领域中,有望带来前所未有的使用体验和便利,例如:实现供应链中各方数据的互通与互信、实现政府或大企业各部门间数据的互联互通、支撑可信追溯相关海量数据的存储等。
以政府大数据建设为例。
在政府众多不同部门和实体间实现高效的数据互联互通一直是个难题。
现行做法往往需要建立独立的大数据部门,构建独立数据存储体系,从不同实体拉取相关数据后解析、重构,再实现可视化。
这往往会带来较大的前期开销,既包含人、财、物等多种显性开销,也暗含人员编制、权责利益、时间成本、部门墙等隐性开销。
同时,独立大数据部门的存在也隐含了需要一个可信第三方背书乃至承担责任的考虑。
如果在这一场景下采用ImSQL作为数据互通的底层基础平台,就可以更为高效的完成这一任务,具体体现在:
什么是ZK-Rollup(零知识汇总)?
以太坊扩容方案有哪些
区块链是如何防止储存诈骗行为的